
51·
8 months agoThanks for that read. I definitely agree with the author for the most part. I don’t really agree that current LLMs are a form of AGI, but it’s definitely close.
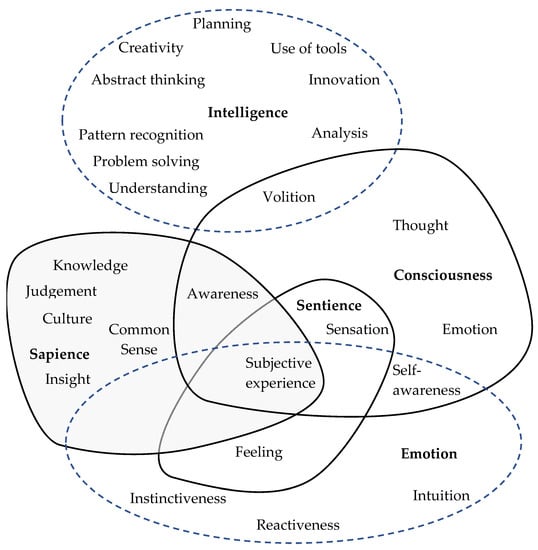
But what isn’t up for debate is the fact that LLMs are 100% AI. There’s no debate there. But I think the reason why people argue that is because they conflate “intelligence” with concepts like sapience, sentience, consciousness, etc.
These people don’t understand that intelligence is a concept that can, and does, exist outside of consciousness.


Maybe waiting to see which side comes out on top. Kinda like Volkswagen. (Yes I know I didn’t exactly happen like that)