

71·
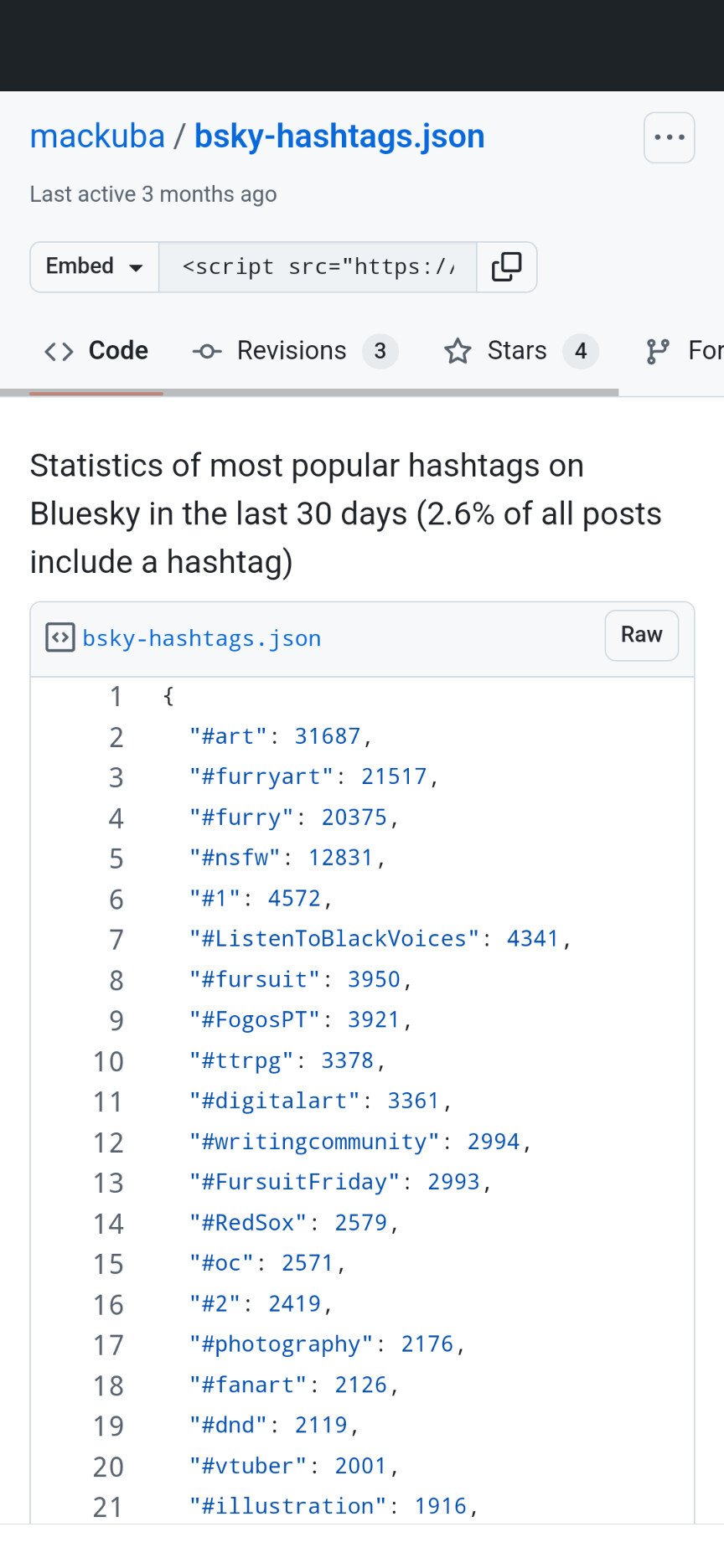
16 days agoI think the author was too generous, the majority of signups are bots/AI mixed with super casual side accounts. 2.2 million Brazilians sign-up in a couple days? I call bullshit. Even if that were true, they signed-up and don’t use it. Why do I believe that?
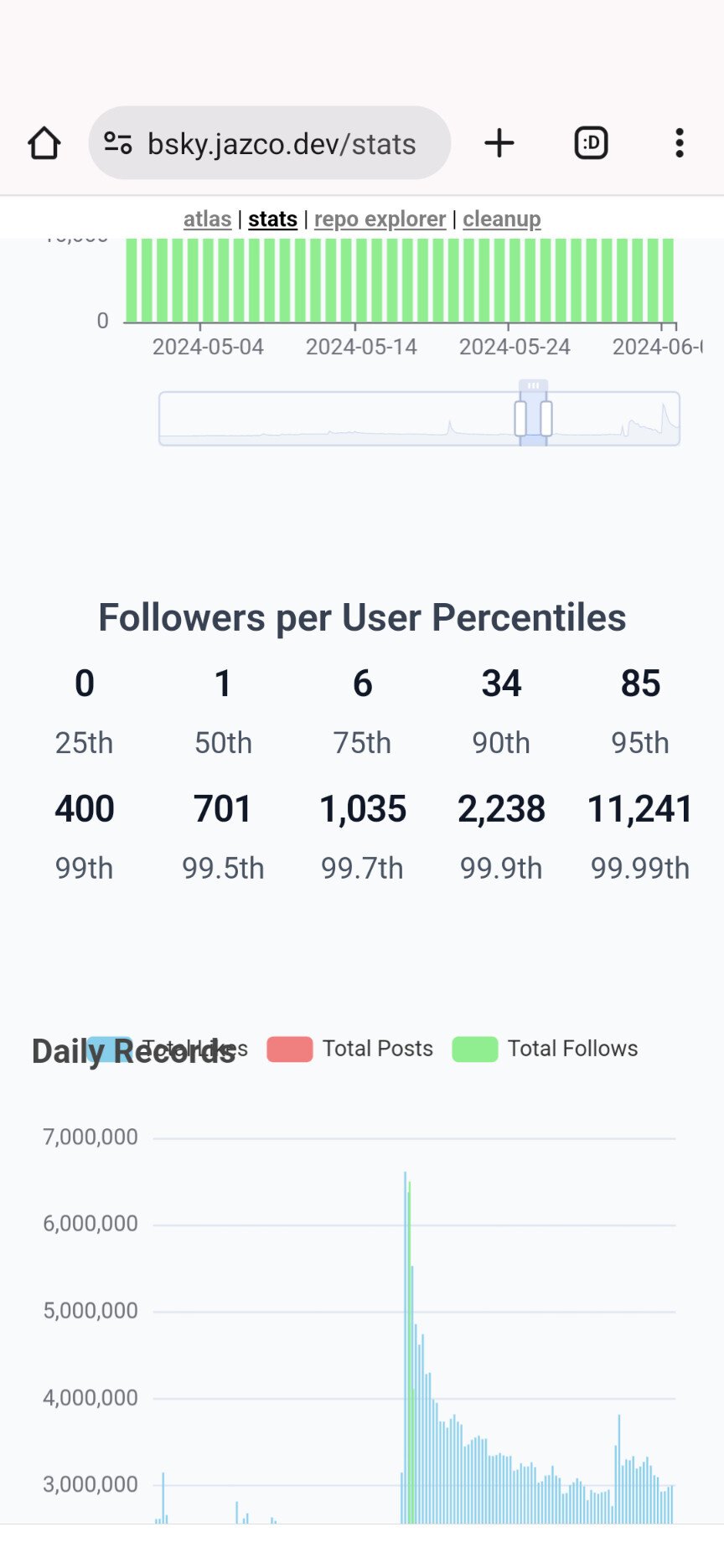
It’s because the awesome account I follow Quanta Magazine gets 20 hearts/likes/whatever and often less than 10, with 0 or 1 comment. Super weak interaction across the whole platform if you check out accounts that should be popular.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Plus, check this out. The platform says I have 12 followers but only 4 show up. Major problems over there.